Why would we need this?
In most applications, LLMs need to be connected to an ever changing set of data. It’s simple enough to parse and embed a few PDF’s. However, managing this data is tedious when you’re working with large, multimodal datasets that consistently need to be updated, re-indexed, and replaced. Plus you’re likely managing multiple databases - one for vectors, and one for your other data. This gets painful really fast.Key Features:
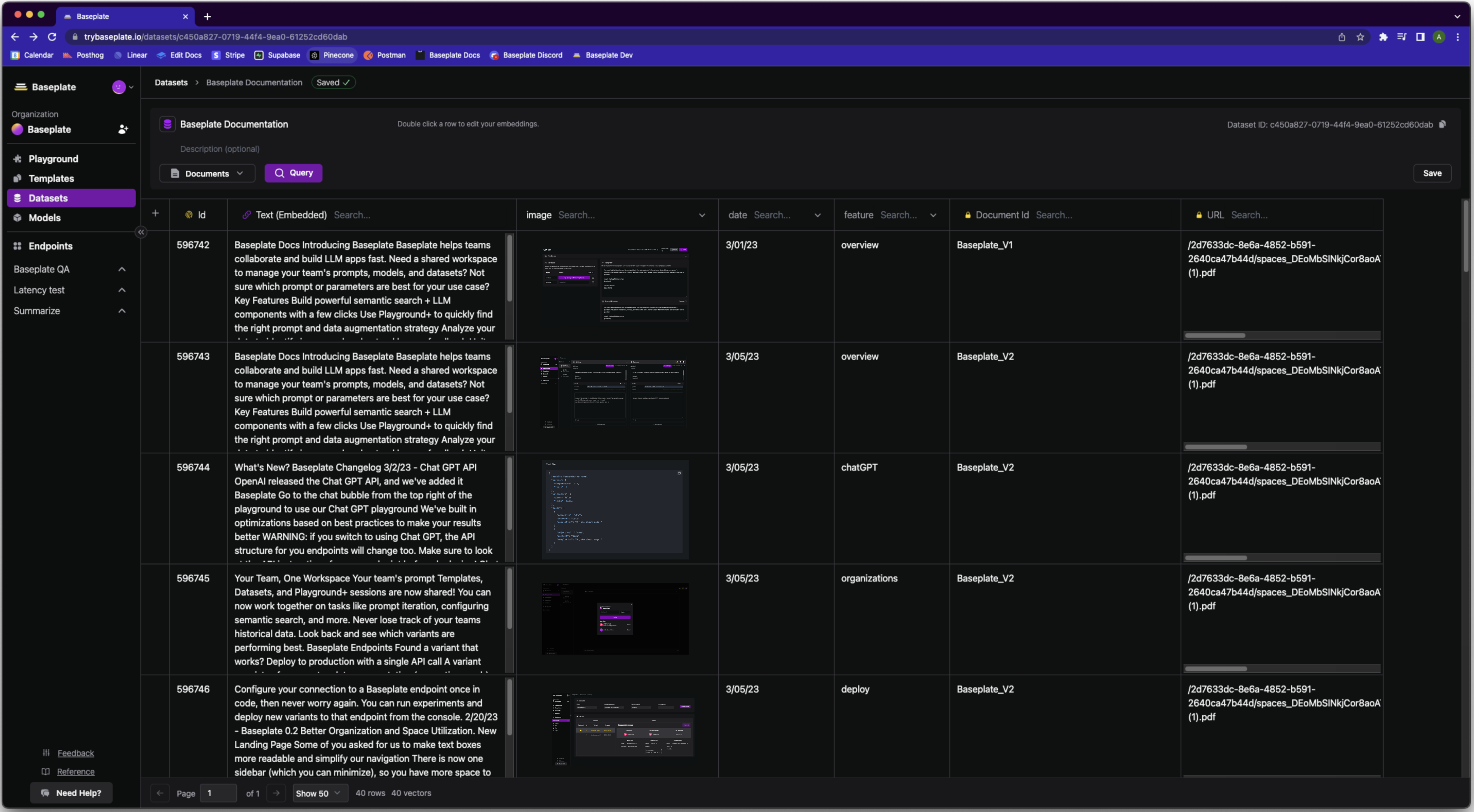
- A flexible hybrid database. A single dataset in Baseplate can contain
- Embeddings
- Text
- Code
- Documents
- Images
- Links
- Database management
- Sync datasets with your tools (Google Drive, S3, Box, Sharepoint, etc.)
- Utilities for updating and managing vectors in bulk
- Organize and segment your data intuitively
- Work in the UI or programmatically via API
- Smart Search
- Choose an embedding model for your use case, tailored for your documents
- Multi-step Search. Retrieve context from multiple datasets within an app.
- Use keyword, semantic, or hybrid search
- Retreive whole documents or just relevant chunks
- App Builder
- Choose between a number of popular LLMs
- Build a custom prompt for your use case
- Test and deploy your app without any code
- Endpoints
- One-click Slackbots, Discord Bots, Teams Bots, and more!
- Build, test, and deploy your Apps via API endpoints
- Unlimited queries
- Built-in utilities for human feedback, logging, & caching