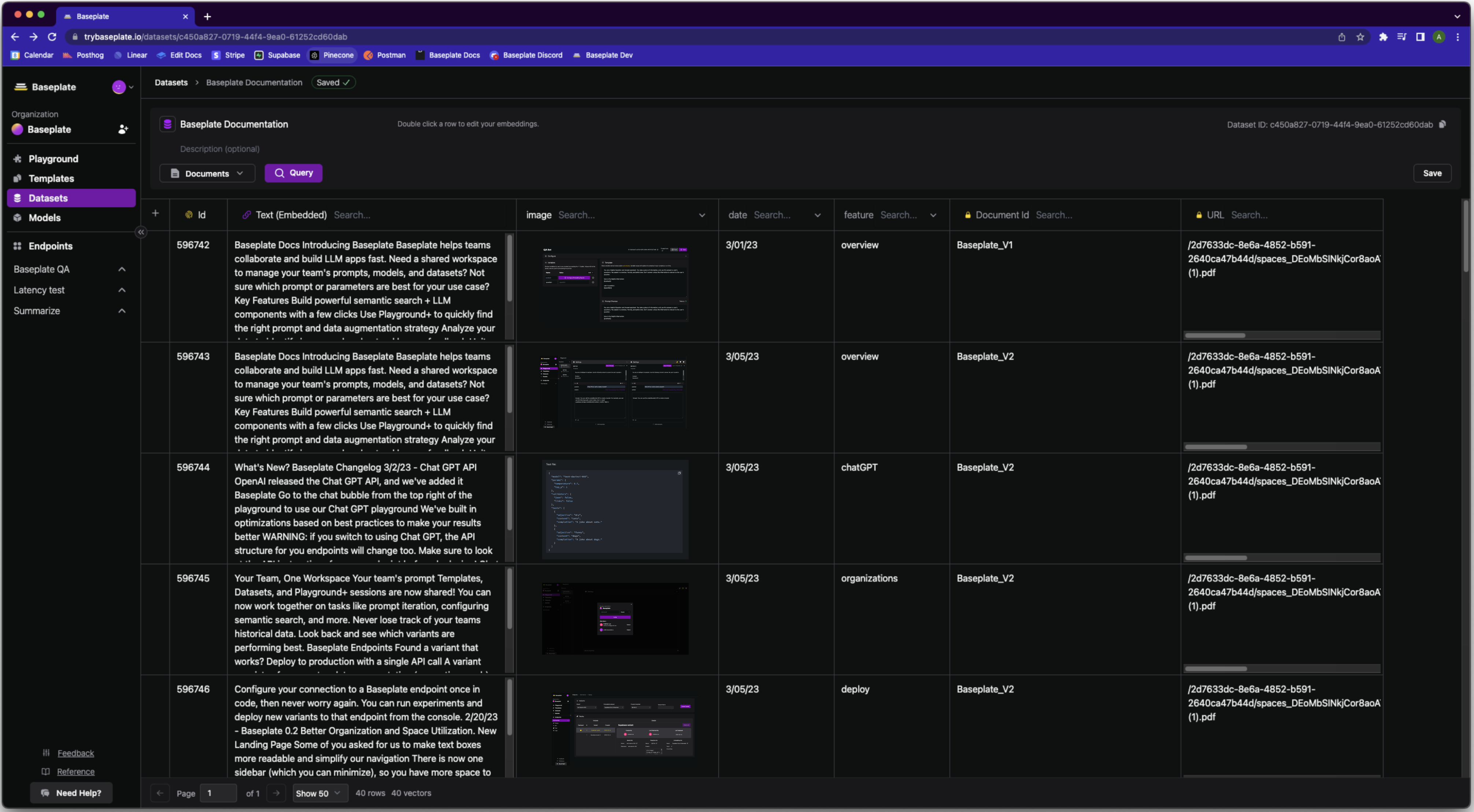
Hybrid database for your regular data and your embeddings
Create Columns
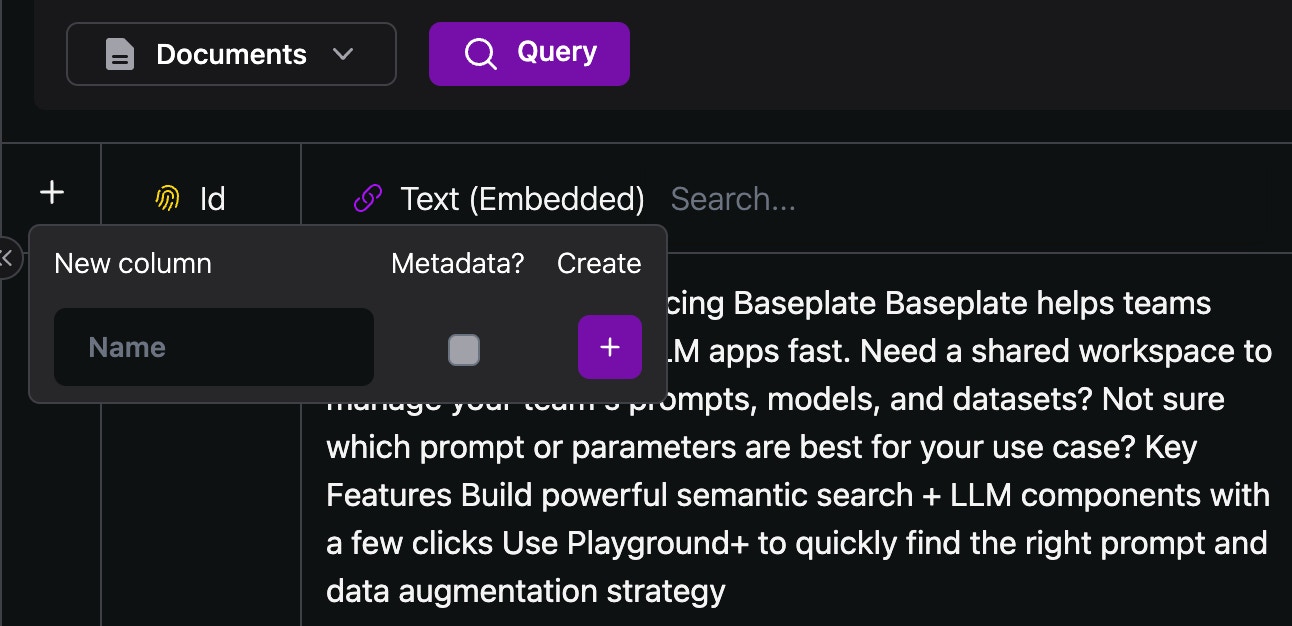
Add data, metadata, and embedding columns
- Embedding Columns
The content in these columns will be embedded using the embedding model you select - Data Columns
Typically images, urls, code snippets, or links that you’d like to be returned with your search result - Metadata Columns
Really useful for large datasets to make sure you’re getting relevant vectors. Segment your data based on customer, datasource, version, date, or whatever your prefer! - Image Columns
Drag and Drop or import images for use as image references.
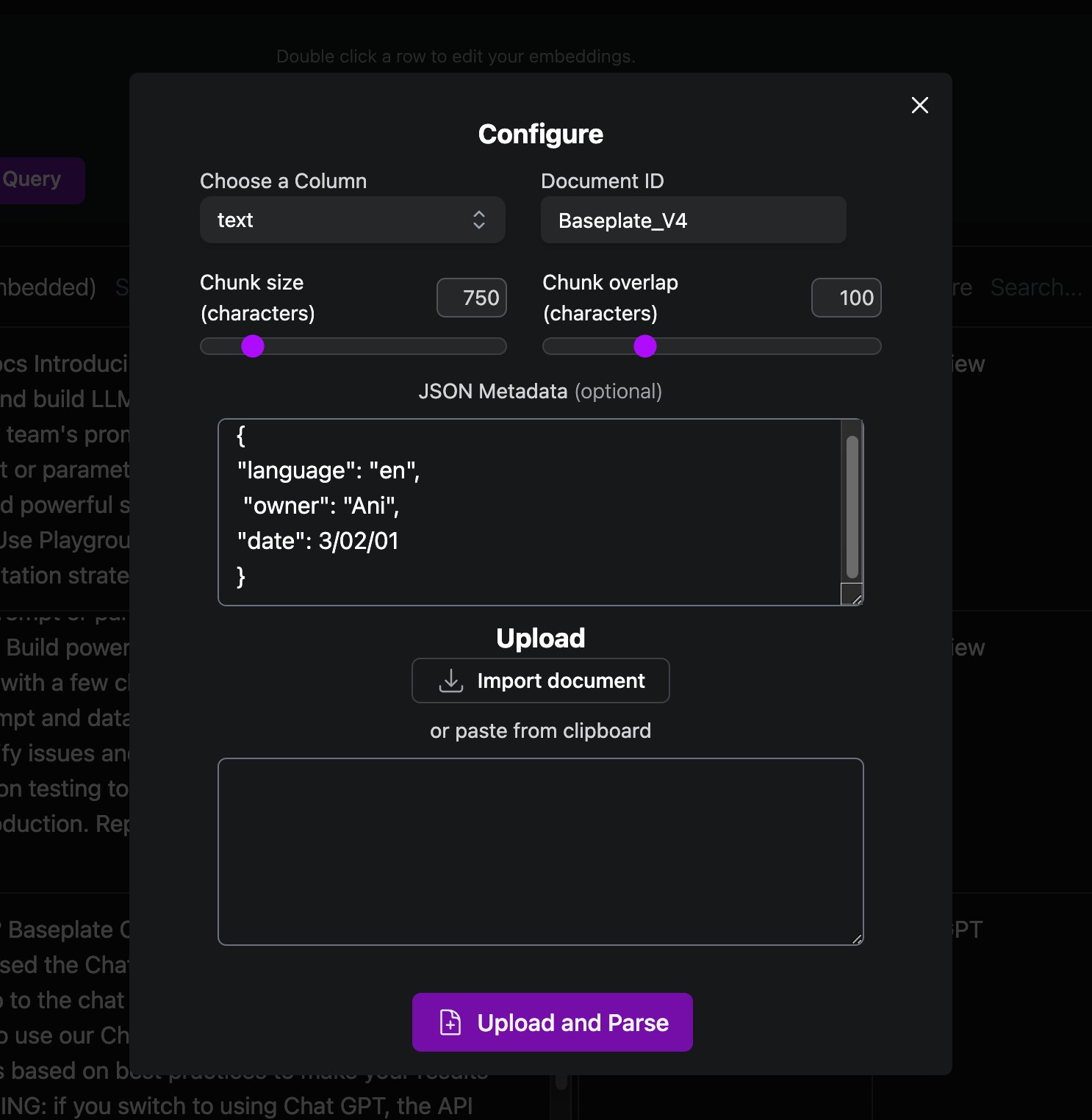
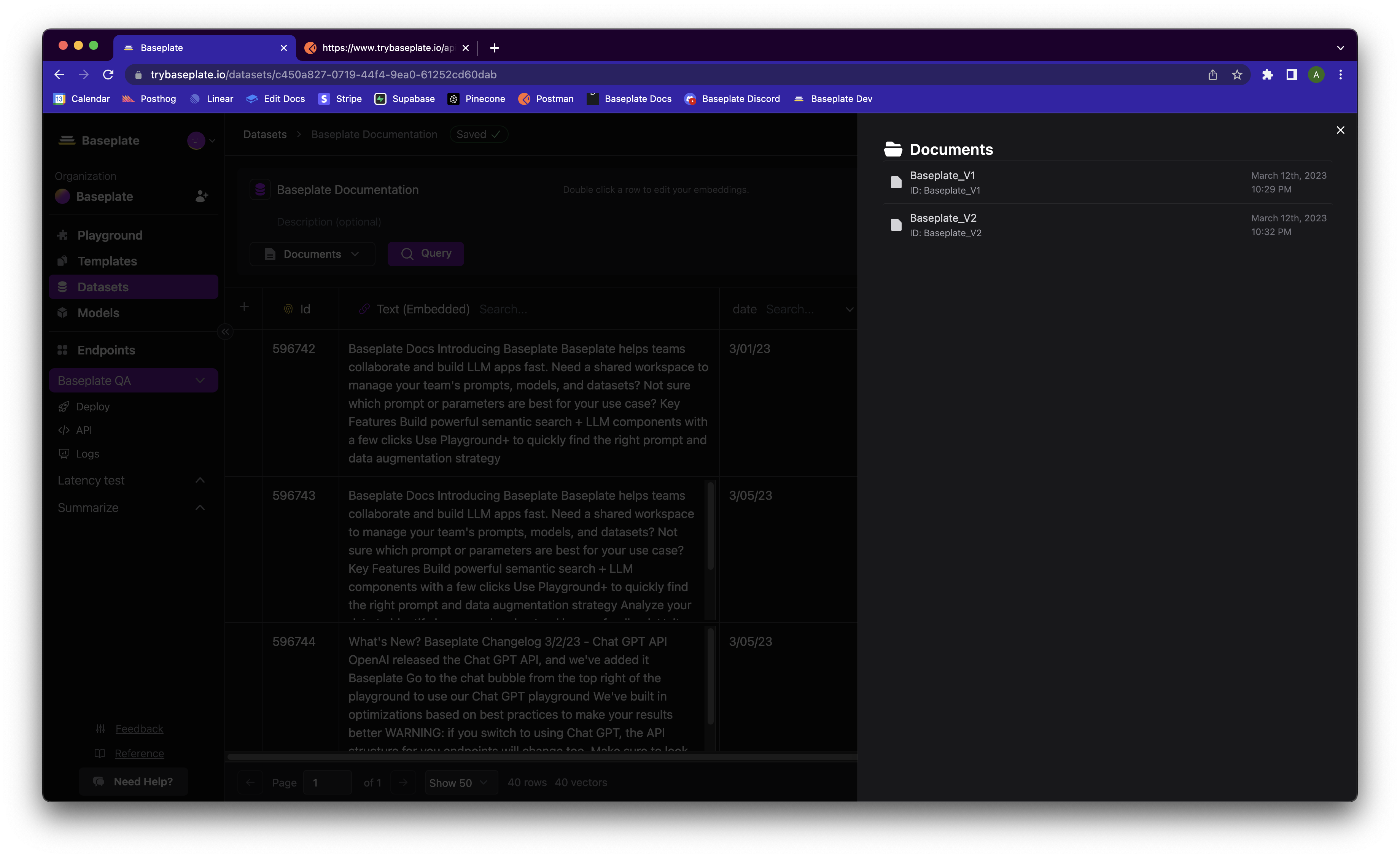
Adding Documents
- Add a whole document
You can use Baseplate’s built in parsing capabilities to break documents into chunks for embedding. Specify a chunk size and which column to add the chunks to, and we’ll do the rest - Add context chunk-by-chunk
For more nuanced indices, upload rows to Baseplate via API once you’ve chunked them
Updating Vectors
Edit your vectors from the interface or through the API. We’ll automatically handle the embedding, updating of your text representation, and upsert of the new vector.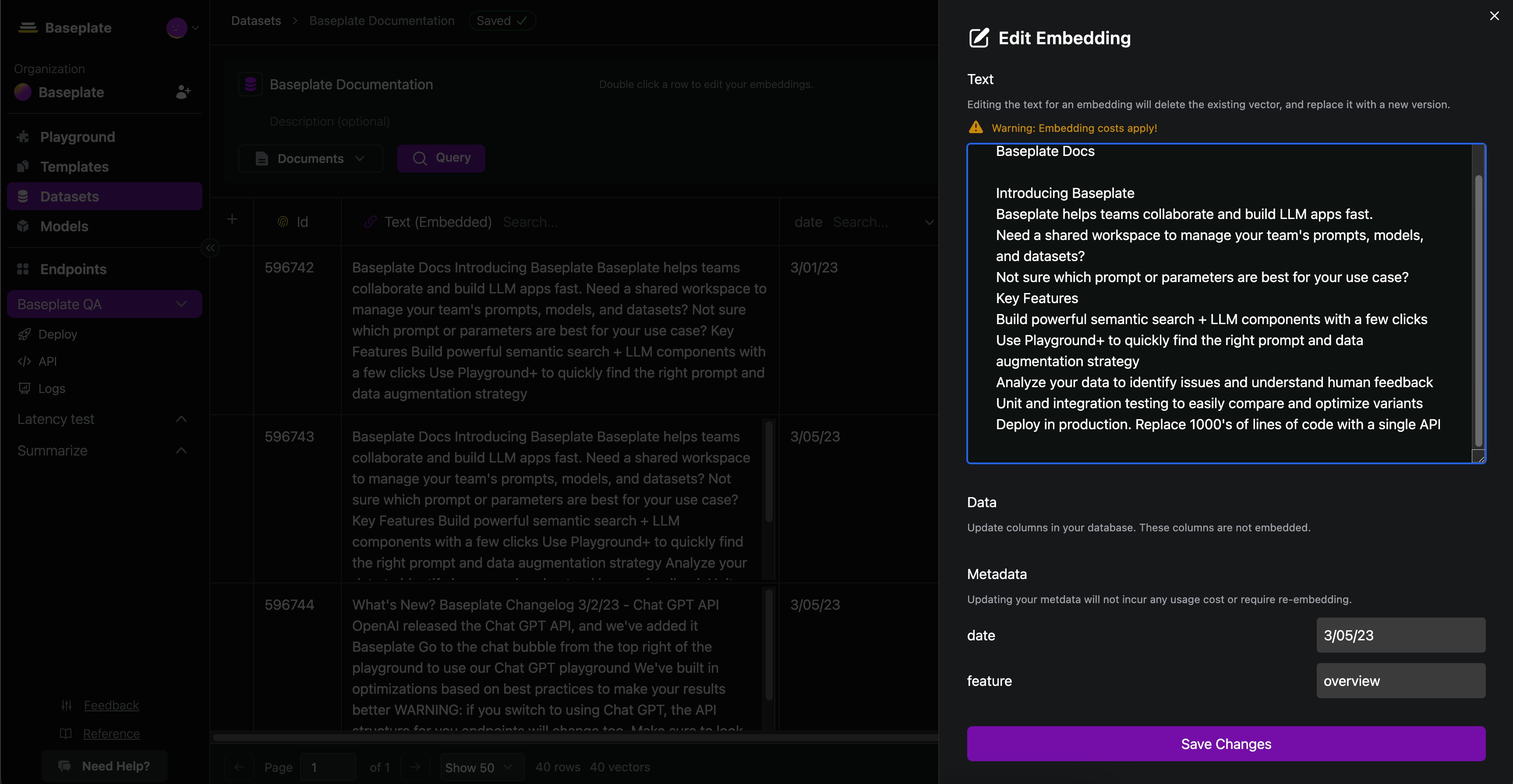
Manage Documents
Manage your Database
Auto Embedding
Automatically caption and embed images.